前言
最近看完了数据库的行式存储后,也想总结下列式存储。列式存储也有多种实现方式,这里挑选熟悉的存储格式 orc,它在hive里使用的比较多。本篇会先讲讲它的设计结构,然后结合源码来理解,中间还会讲述一些配置项的调优。orc 项目的代码地址为,这里吐槽下它的代码结构有点乱,看起来真的很费劲。
文件结构
文件结构如下图所示,来自官方网站
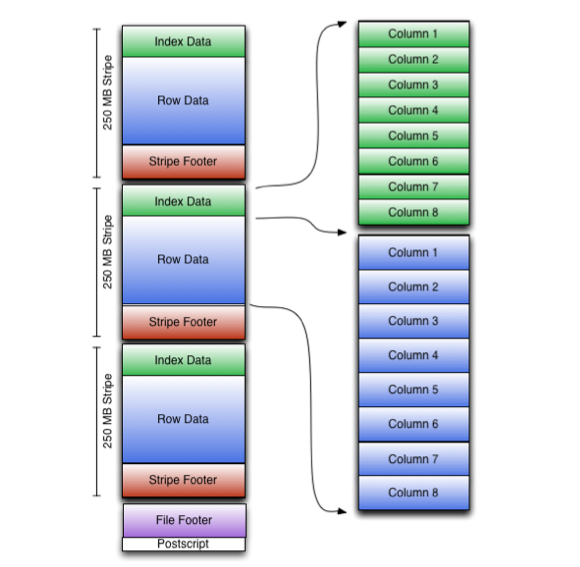
整个文件分为 Stripe 数据部分,OrcTail 部分。OrcTail 部分包含了整个文件的元数据,分为 PostScript 和 Footer 。PostScript 里面包含了压缩信息。Footer 包含列定义,和一些统计信息。比如多少行数据,每列的统计信息(最大值,最小值,总和值)。还包含了各个 Stripe 的信息。
数据都被分割成一块块的,存储在每个 Stripe 里。每个Stripe 还包含了里面数据的统计信息和布隆过滤器,
rowIndexStride 表示单个 索引项 RowIndex 的元素,最多包含的行数。
具体内容可以参考 proto 文件,orc 使用了 protobuf 来定义这些数据。也可以参考官方文档。
数据交互单位
再继续介绍数据的读写之前,需要详细介绍下,它对外接口提供的数据单位VectorizedRowBatch,它表示多行数据。它是将每列的数据单独存储。
|
|
ColumnVector表示一列的数据,可以看作是一个数组。ColumnVector有多个子类,每个子类对应于一种数据类型。
|
|
列统计信息
对于列的统计信息,orc 会有不同范围的统计。有基于整个文件的统计,有基于 stripe 的统计,还有基于 stripe 中的 row group 的统计。这些统计信息由ColumnStatistics表示,它还有多个子类,每个子类对应一种数据类型。
ColumnStatisticsImp中存储了这些类型中相同的部分信息
|
|
下面以 int 类型为例,它还有独立的统计信息
|
|
数据写入
在了解了文件结构之后,接下来就继续了解它是如何写的,这样才能进行一些针对性的调优。
数据写入流程
整体写入过程不是很复杂,下面是相关源码
|
|
是否需要创建索引由orc.create.index配置项指定,一般都是允许,这非常有利于优化读的优化。orc 创建的索引很明显是稀疏索引,它是每隔一定的行数,才会创建。这个阈值由orc.row.index.stride配置项指定,默认为 10000。如果我们需要更加稠密的索引,可以适当的将这个值调小。不过这会造成数据存储的一定程度增大。
同样在添加完一个 batch 的数据之后,它每隔orc.rows.between.memory.checks条数据,就触发一次内存检查。查看该 stripe 的所占的内存是否超过了orc.stripe.size字节,超过了就会刷新该stripe,并且创建新的 stripe。不过这个触发是在每次添加完一个 batch 之后。所以如果我们想精确的控制 stripe 的大小,那么就需要控制每次 batch 的数据尽量小。
对于内存控制,还有一个配置项orc.memory.pool,它表示写 orc 文件时,stripe 数据最多占用JVM Heap 空间的百分比,默认为50%。所以在设置 jvm 的 heap 值时,还需要集合orc.stripe.size考虑。
Stripe 跨 block 问题
orc 在存储 stripe 时,会尽量保证 stripe 不会跨 block,。通常一个 block 会包含多个 stripe,如果新增的 stipe 不能完整的存储到一个 block 中,那么会添加空值填满该 block。这样 stipe 就能存储在下个 block了。
block 大小由orc.block.size指定, orc.block.padding指定了是否允许添加空值。同时填充的空值空间大小由限制,为orc.block.padding.tolerance * orc.stripe.size。因为 hdfs 存储数据是以块为单位的,orc 存储也是基于 hadoop 环境产生的,为了在进行计算时,每个任务对应一个 block,如果 stripe 不跨域block 的话,那么就非常完美。一般来说orc.block.size值等于 hdfs 的 块值。
布隆过滤器
orc 不仅支持常见的数据统计,比如最大最小值,是否有空值等,用户在读取数据时,可以充分的利用这些信息来快速的过滤数据。它还支持布隆过滤器,这个过滤器只能判断某个值是否不存在。
数据读取
读取流程
接下来就是文件读取的流程了。在读取开始时,会先读取文件的元数据。然后,依次读取 stripe 里的数据,结合 row group 索引,可以快速的过滤数据,提高读取性能。
比如一个 int 类型的列,它对应的 row group 索引,包含了最大最小值,这样当遇到大于或者小于或者等于的时候,就可以快速得判断该区间的数据是否符合。
除此之外还有布隆过滤器,当需要查找某个值是否不存在该集合里,就能快速的判断。
源码
读取操作从ReaderImpl类开始,它在读取完整个文件的元数据后,就会调用rows返回RecordReader,负责读取里面的数据。
RecordReader的提供了nextBatch方法,负责实际的数据数据。读取流程如下:
readStripe方法,会读取该 stipe 的索引,计算哪些 rowgroup 需要读取。pickRowGroups负责根据 row group 索引和 布隆过滤器,选择需要遍历的 row group。advanceToNextRow方法,实现了利用 row group 索引,来快速的过滤行。
我们在读取数据之前,需要设置SearchArgument过滤条件,才能充分利用这些索引。还需要注意下,orc 只会过滤那些 row group,里面的数据完全不符合条件的。所以返回的数据,还需要我们再过滤一次。